How Python orchestrates financial domain logic, quantitative research, modern MLOps, and production operations — in the reality of 2026.
The Story: When a Great Notebook Falls Apart in Production
Every fintech company and every hedge fund has seen some version of this story.
A quant researcher builds a promising strategy in a Jupyter notebook. The signal looks strong, the backtest curve is smooth, the Sharpe ratio is impressive. Clean historical data, a few pandas transformations, some NumPy math, a well-tuned model. In the research environment, everything looks convincing.
Then the engineering team tries to move it into production.
Suddenly the model behaves differently. Market data arrives with missing values. Corporate actions (splits, dividends) were not handled the same way as in research. Timestamps are not aligned across exchanges. The backtest assumed execution at the close price, while the real system faces slippage, liquidity constraints, broker latency, and partial fills. On top of that, wrapping the heavy pandas processing in a simple FastAPI endpoint freezes the entire microservice under concurrent load.
The issue is not that Python failed. The issue is that the organization treated Python as a standalone research tool, ignoring the realities of distributed systems, concurrency, and MLOps.
The real question is not: “Can Python build fintech systems?” The real question is: where does Python create the most enterprise value, and what architectural guardrails make it safe enough for financial production?
Enterprise Fintech Is a Layered Architecture
A fintech or quant platform is not one application. It is a layered system of money flows, risk decisions, provider integrations, order execution, data pipelines, and operational controls.
Python is not a silver bullet. Mature architects do not write ultra-low-latency HFT engines or core banking ledgers in Python. There, C++, Rust, Java/Kotlin (especially with Project Loom now mature), and occasionally OCaml (Jane Street) dominate.
Python’s strength is acting as the strategic glue. Under the hood, Python rarely does the heavy lifting itself:
- NumPy is written in C and links against BLAS/LAPACK (OpenBLAS, MKL, Apple Accelerate); heavy vector operations release the GIL.
- Polars is written in Rust on top of Apache Arrow, uses SIMD and native multi-threading.
- PyTorch is C++/CUDA.
- Pydantic v2 is Rust-backed (
via pydantic-coreandjiter). - orjson and msgspec are Rust/C for fast JSON.
Python provides the expressive, domain-oriented API on top of these engines.
Python is uniquely positioned for:
- risk analytics, portfolio optimization, and forecasting;
- data engineering and feature pipelines;
- quant research and strategy backtesting;
- mid-frequency trading (MFT) and execution orchestration;
- ML/LLM compliance copilots and document intelligence;
- internal operations platforms and reconciliation.
In the largest quant shops (Hudson River Trading, Citadel, Two Sigma, Jane Street, D. E. Shaw), Python lives at the research, feature engineering, and orchestration layers. The hot path — order routing, market-data gateway, matching — is almost always in C++, Rust, OCaml, or Java.
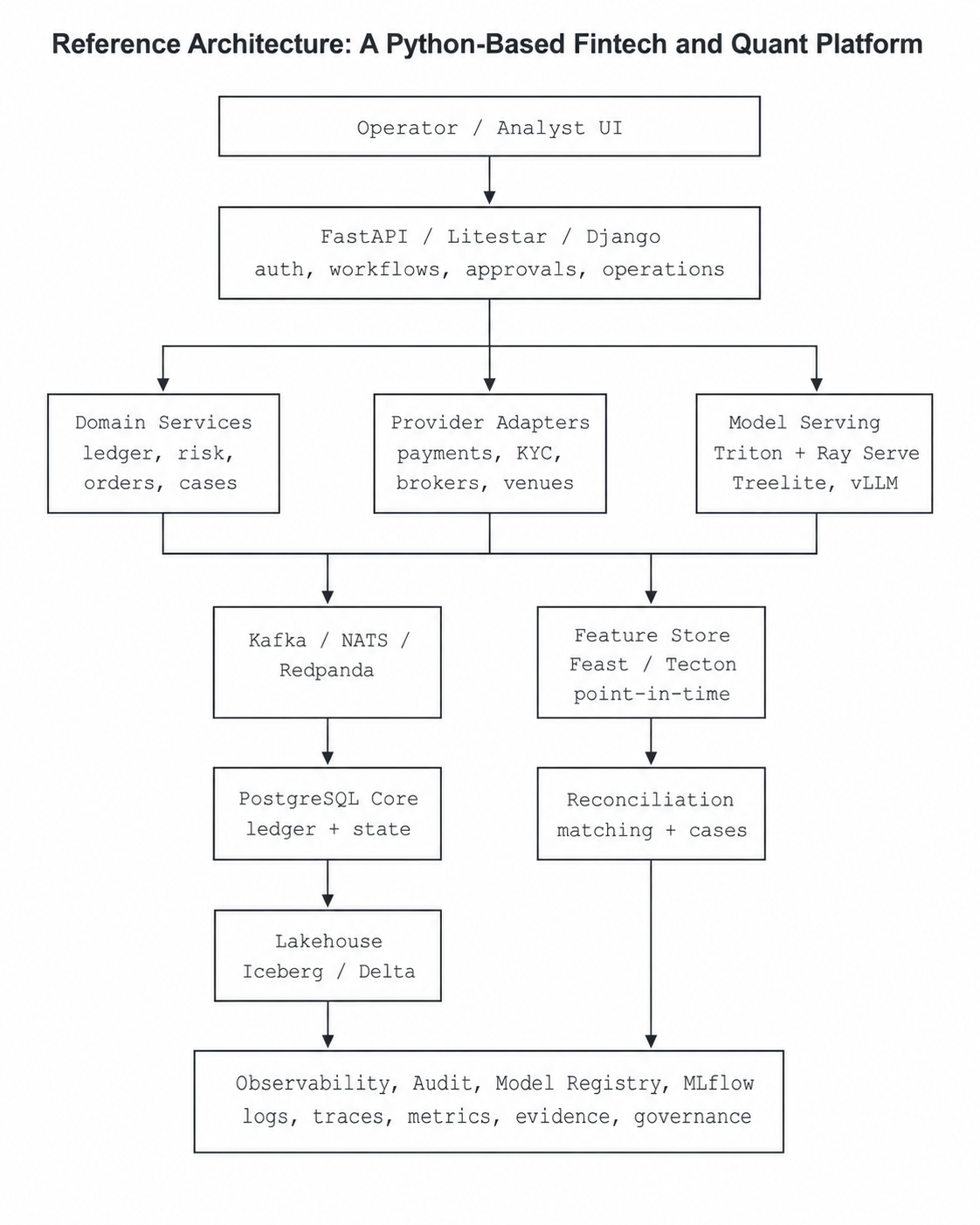
Reference Architecture: A Python-Based Fintech and Quant Platform
Beyond FastAPI: Modern MLOps and Model Serving
Wrapping a pandas DataFrame and an sklearn model in a FastAPI endpoint is fine for a demo. It is an anti-pattern for a production quant platform. Mature MLOps requires strict separation of concerns.
Model Serialization — More Than Just ONNX
A model should not be tied to the specific Python environment or library version of the research team. The canonical formats are:
- ONNX (Open Neural Network Exchange) — for neural networks. Decouples the model from Python, runs on a C++ runtime (ONNX Runtime), supports quantization and hardware acceleration.
- Treelite, or the native C APIs of XGBoost / LightGBM — the main path for tabular gradient-boosting models, which remain the workhorse of quantitative research. Treelite compiles trees into native code with single-digit microsecond inference latency per vector.
- TorchScript or
torch.compile+ AOT inference — for PyTorch models where ONNX conversion loses precision or operators. - Pickle — never in production. Insecure, version-fragile, tied to specific Python and library versions.
Specialized Inference Servers
For heavy inference, instead of generic web frameworks, teams use:
- NVIDIA Triton Inference Server — dynamic batching, model versioning, multi-framework (TensorFlow, PyTorch, ONNX, TensorRT, XGBoost via the FIL backend), strong on GPU workloads.
- Ray Serve — Python-native, great for model composition and business logic, autoscaling, and complex inference DAGs.
- vLLM — for LLM workloads (compliance copilots, document processing).
In real-world stacks Triton and Ray Serve are not competitors but complements: in 2024 NVIDIA and Anyscale released a joint solution where Ray Serve orchestrates business logic and Triton acts as a high-performance inference backend. That is the production pattern of 2026, not “either/or.”
The Quant Model Lifecycle
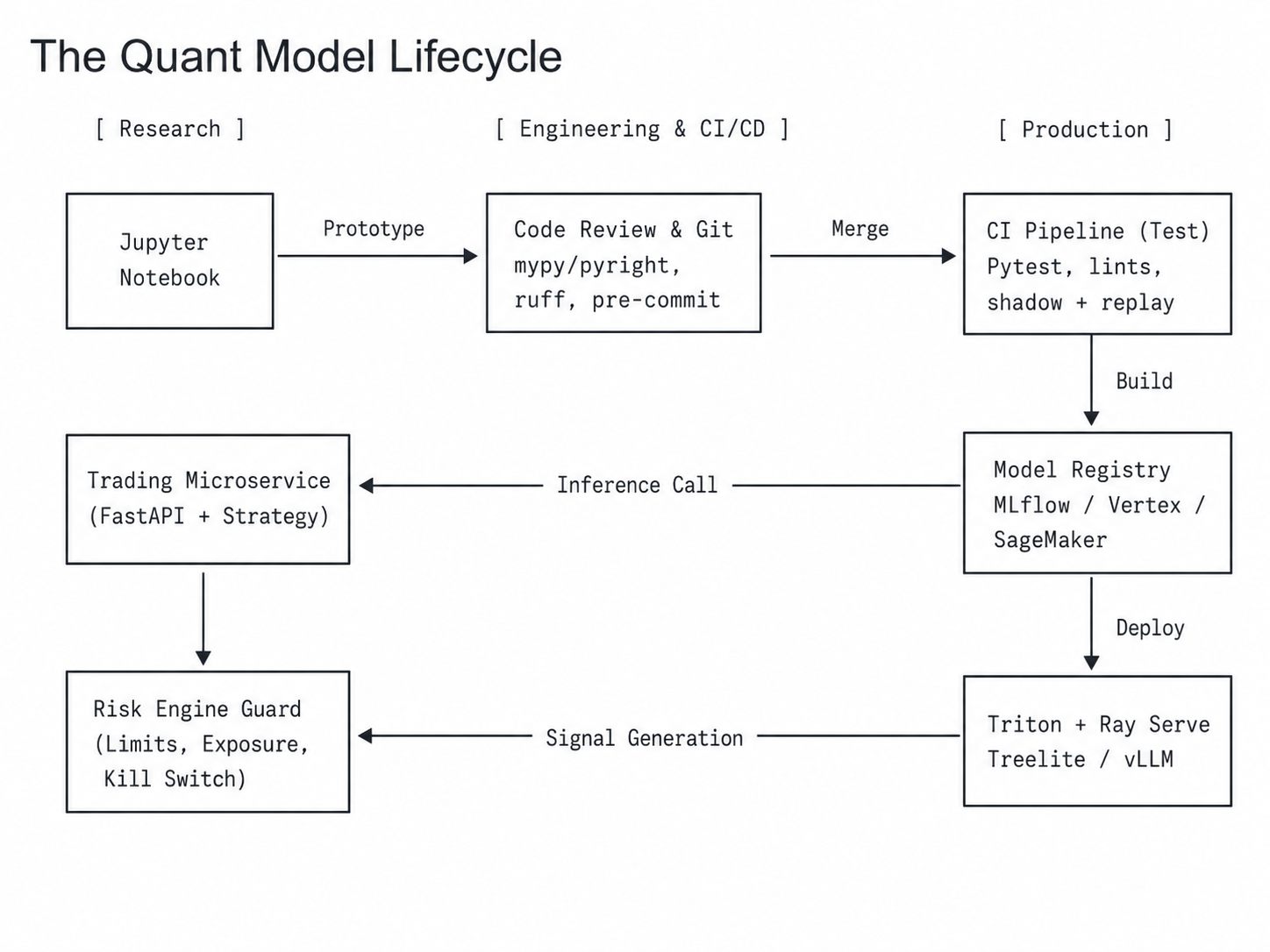
The shadow + replay stage is a separate control: a new model runs “in the shadow” of the live one for a period, with its decisions logged but not executed. The Python stack handles this naturally — the same container, the same features pulled point-in-time-correctly from the Feature Store, the same model registry.
Performance: The GIL Is Not What It Used to Be
When a Python service in fintech is slow, juniors blame the language. Seniors look at the architecture. By 2026, it is critical to understand that the classical GIL narrative is obsolete — and at the same time, that naively switching everything to free-threading is also a mistake.
The State of the GIL in 2026
- PEP 703 was accepted in July 2023.
- Python 3.13 (October 2024) shipped an experimental free-threaded build (
python3.13t). - Python 3.14 (2025) moved free-threading from experimental to officially supported (PEP 779). The single-thread overhead is now around 5–10%.
- The roadmap: by 2028–2030 the GIL is expected to be off by default.
- In parallel: PEP 684/734 introduced subinterpreters — isolated interpreters within a single process, also GIL-free with respect to each other, available since 3.12 (C API) and 3.14 (the
interpretersmodule in stdlib).
What this means in practice:
- A pure-Python Monte Carlo on free-threaded 3.14 actually scales across cores without
multiprocessingoverhead. - On standard CPython, NumPy already releases the GIL during vector operations —
ThreadPoolExecutor+numpyworks today even without free-threading. - Subinterpreters are a middle ground between
threadingandmultiprocessing: process-like isolation with thread-like cost. Useful for multi-tenant pricing services.
Free-threading is not magic. The main cost is thread safety: code written under the assumption “the GIL serializes things for me” breaks. C extensions must explicitly support free-threading (the Py_GIL_DISABLED flag); many still do not.
Async and Event Loop Blocking
asyncio is excellent for I/O-bound tasks: market-data feeds, REST calls to providers, databases. But any synchronous CPU-heavy operation inside an async handler blocks the entire event loop and adds latency to every concurrent request.
Classical mistakes:
- The standard library
json.loadson large payloads. Solution:orjson(Rust, 2–5× faster) ormsgspec(C, even faster, plus type-hint-based validation — and on pure decoding it benchmarks faster thanorjsoneven with validation enabled). - Heavy
pandasorpolarstransformations inside an async handler. Solution: offload toasyncio.to_thread/run_in_executor(NumPy/Polars release the GIL during vector ops) or to a separate worker process via a queue. - Pydantic validation on enormous models. Solution: Pydantic v2 (Rust-backed via
jiter) is already faster than most hand-rolled alternatives; for the critical path,msgspec.Structis faster still.
Garbage Collection and Latency Consistency
For MFT, latency consistency matters. CPython’s cyclic GC can introduce unpredictable millisecond pauses on large object graphs. Industrial practices:
gc.disable()during a trading burst,gc.collect()in the windows between sessions;- use slotted classes (
__slots__) ordataclass(slots=True)— fewer objects, less work for the GC; - keep hot data structures in NumPy/Polars — Arrow buffers do not touch the Python refcounter per cell;
on action paths — move to Cython/cffi or rewrite in Rust via PyO3 (as Polars and Pydantic have done).
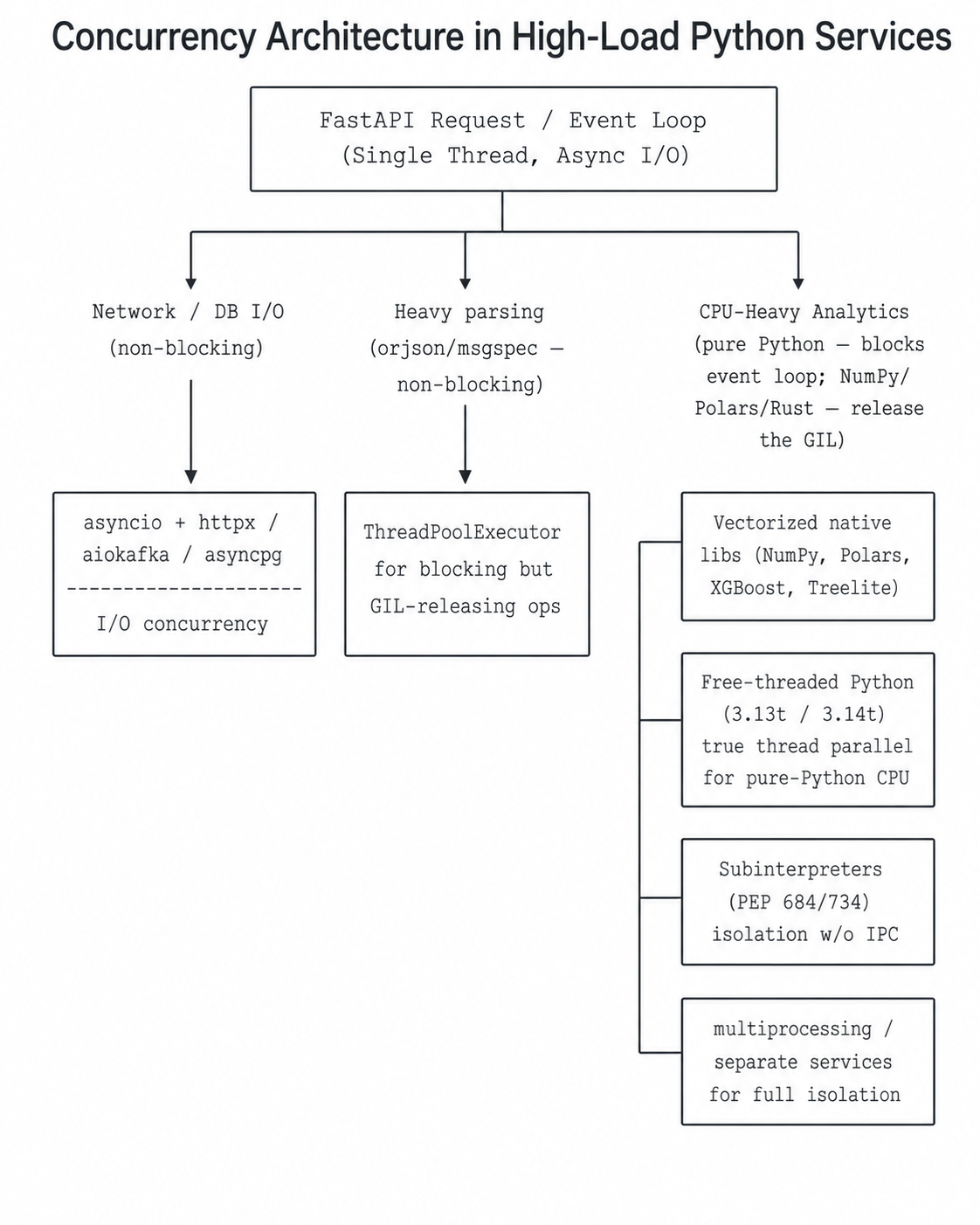
The choice should follow the workload, not fashion. In most fintech services, the production deployment is still gunicorn -k uvicorn.workers.UvicornWorker with N processes and async inside.
The Data Layer: Governing Biases and Assumptions
Most quant model failures are caused by unstated data assumptions, not the model itself:
- Survivorship bias — the strategy uses today’s index constituents to simulate trades five years ago.
- Look-ahead bias — a feature accidentally uses data not known at trade time.
- Data leakage — the target variable (or a proxy of it) leaks into training features.
- Time alignment — different exchanges (NYSE, LSE, MOEX) operate in different sessions and time zones, and without explicit normalization this creates “magical” alpha.
A mature data layer treats these assumptions as first-class versioned artifacts. The technical answer is a Feature Store with point-in-time joins:
- Feast — open-source, pluggable on top of Spark/Snowflake/BigQuery/Redis.
- Tecton — managed, end-to-end, including transformations.
- Hopsworks — strongest in regulated industries (lineage, audit, governance).
- Databricks Feature Engineering / Vertex AI Feature Store — for single-cloud shops.
A point-in-time-correct join guarantees that for a training row with timestamp t, only the feature values known before t are joined in. This technically eliminates look-ahead bias rather than relying on convention.
from dataclasses import dataclass
from datetime import datetime
@dataclass(frozen=True)
class FeatureSnapshot:
dataset_version: str
feature_view: str # name in the Feature Store
feature_version: str
as_of_timestamp: datetime # event time, not ingest time
universe_id: str # snapshot of index constituents at as_of
corporate_actions_policy: str # adjusted / unadjusted / split-only
survivorship_bias_guard: bool
lookahead_bias_guard: bool
timezone_policy: str # exchange-local / UTC / settlement-localThis metadata bridges the gap between a researcher’s CSV and a production Feature Store, and makes the system auditable — for the regulator and for the quants themselves a year later, when “no one remembers anymore.”
Strict Typing and Operational Guardrails
Python in an enterprise fintech setting without static typing is a refactoring nightmare. mypy/pyright in CI, ruff for linting, pre-commit hooks — mandatory. Pydantic v2 at system boundaries (APIs, Kafka messages), dataclass(frozen=True) or msgspec.Struct for internal DTOs.A model deployment is never “expose .predict() over an endpoint.” It is a computational pipeline with explicit guardrails:
from typing import Protocol
import logging
logger = logging.getLogger(__name__)
class QuantStrategy(Protocol):
async def score(self, features: "FeatureFrame") -> "Signal": ...
async def execute_strategy(
request: "SignalRequest",
model: QuantStrategy,
feature_store: "FeatureStore",
risk_engine: "RiskEngine",
kill_switch: "KillSwitch",
) -> "ActionResponse":
# 0. Global kill switch — above everything
if kill_switch.engaged:
return ActionResponse(action="NO_TRADE", reason="KILL_SWITCH")
# 1. Load features from a governed source, point-in-time-correct
features = await feature_store.load(
instrument=request.instrument,
as_of=request.as_of,
)
# 2. Guardrail: data freshness. Threshold is a strategy property, not a magic constant
if features.is_stale(max_age=request.strategy.max_feature_age):
return ActionResponse(action="NO_TRADE", reason="STALE_FEATURES")
# 3. Guardrail: feature distribution drift
if await features.drift_score() > request.strategy.drift_threshold:
logger.warning("feature_drift_detected", extra={"req": request.id})
return ActionResponse(action="NO_TRADE", reason="FEATURE_DRIFT")
# 4. Inference — stateless, idempotent
signal = await model.score(features)
# 5. Guardrail: risk limits and exposure
if await risk_engine.violates_limits(signal, request.instrument):
return ActionResponse(action="NO_TRADE", reason="RISK_LIMIT_EXCEEDED")
return ActionResponse(
action=signal.action,
target_allocation=signal.target_allocation,
decision_id=request.id, # for reproducibility and replay
)The hierarchy is explicit: kill switch → data → drift → model → risk limits. The model is in the middle, not at the start or the end. Every decision carries a decision_id — at any later moment a deterministic replay can reproduce it bit-for-bit: same features, same model version, same outcome.
Position and PnL Reconciliation
In a quant platform you cannot rely solely on your own execution logic. A broker venue can drop an execution report. An API can acknowledge an order but fail to route it. An ECN can report a trade with delay.
The answer is reconciliation. Unlike payment-gateway reconciliation, trading reconciliation deals with rapidly changing state: internal fill ledgers vs. exchange execution reports, open positions vs. venue order books.
In real life this is built around FIX DropCopy — a separate FIX session over which the exchange or broker pushes a “carbon copy” of all executions, order statuses, cancels, and rejects. The canonical use case for DropCopy is exactly near-real-time risk control and reconciliation; CME, ICE, Cboe, Nasdaq, and Binance Institutional all expose DropCopy gateways. Compliance and risk systems subscribe to it independently of the main order flow.
The Reconciliation Engine
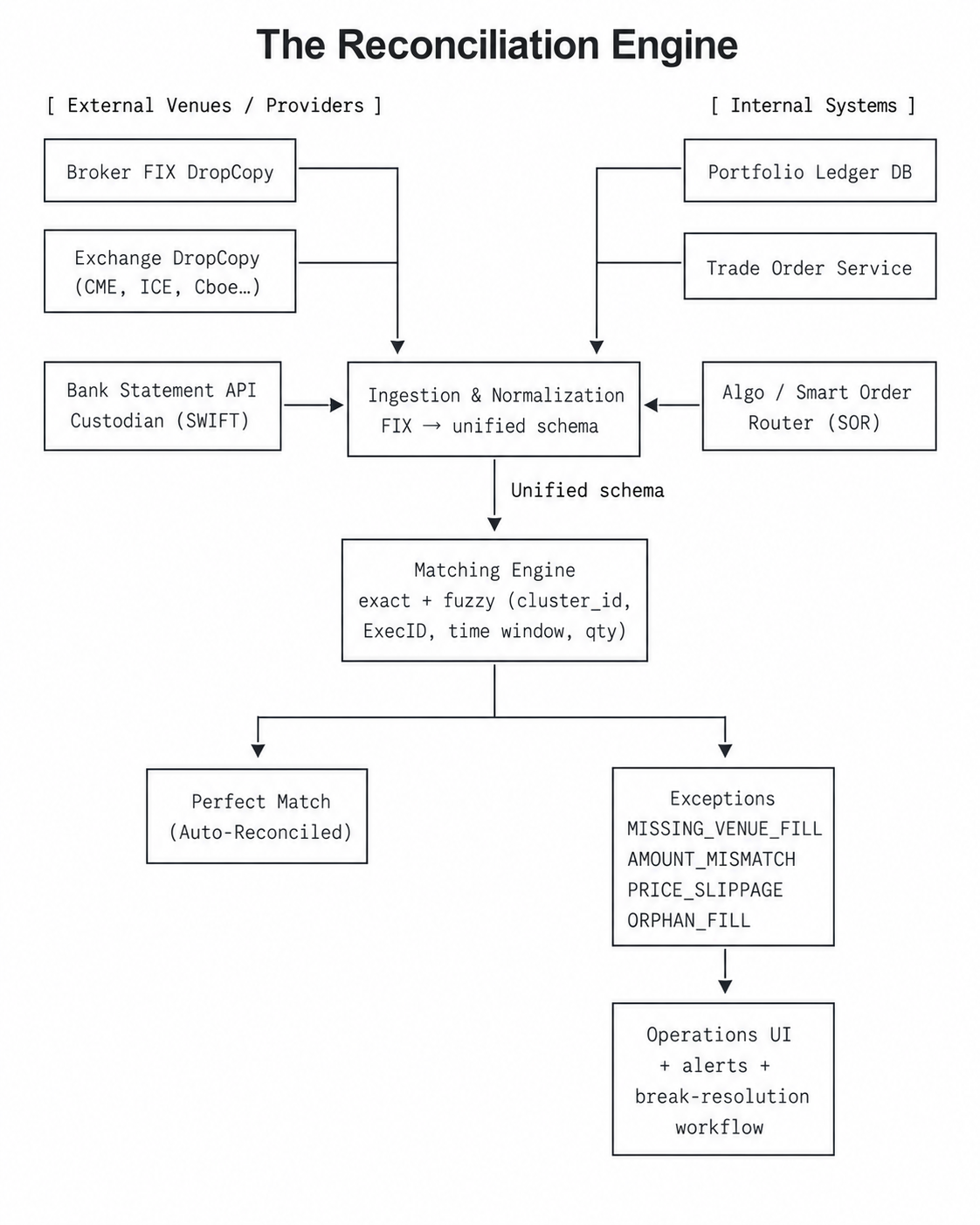
Python is a great fit here because reconciliation is business-logic-heavy, not tick-to-trade-latency-heavy. Parsing FIX logs, REST/SFTP exports, normalization into a unified schema (Polars/Arrow), matching (exact plus fuzzy on time windows and quantities), classification of exceptions (MISSING_VENUE_FILL, PRICE_SLIPPAGE, ORPHAN_FILL), and the break-resolution workflow with full audit trail — all of this maps idiomatically onto the Python stack.
LLM Copilots and Document Intelligence
A section that did not exist in earlier versions of this kind of article — and by 2026 is no longer futurism but production:
- Compliance copilot: summarizing reg-bulletins (SEC, ESMA, FCA), mapping them to internal policies, drafting responses to regulatory inquiries. Architecturally — RAG on top of a vector database (pgvector, Qdrant, Weaviate), orchestration via LangGraph or plain Python.
- Document intelligence: extracting data from term sheets, ISDA confirmations, KYC documents. LLM with function calling + strict Pydantic validation of outputs + human-in-the-loop on edge cases.
- Quant research assistant: helping with feature exploration, code review of backtests, detection of common look-ahead bugs.
The important point: all of this requires the same guardrails as trading models. Prompt versioning, evaluation sets, drift monitoring on responses, audit logs. An LLM in fintech without observability and without human-in-the-loop on critical decisions is just another way to attract regulator attention.
Business Value: The Strategic Layer
For business stakeholders this is not a language debate but a question of platform maturity.
A well-built Python fintech architecture lets a company:
- safely promote quant experiments to production through a single Feature Store and model registry;
- reduce operational risk through DropCopy-based reconciliation and explicit guardrails;
- use modern MLOps (Triton + Ray Serve, Treelite, ONNX, vLLM) to scale inference efficiently;
- build LLM and document-intelligence workflows on top of governed, typed data;
- avoid the classical Python pitfalls (GIL, GC pauses, event-loop blocking) through a combination of async architecture, free-threading on 3.14+, subinterpreters, and native Rust/C engines.
The strongest fintech platforms do not treat Python as “just a notebook language.” They use it as a strategic orchestrator for financial workflows, data intelligence, model governance, and operations. Given engineering discipline — typing, guardrails, MLOps, architectural awareness of performance — Python is, in 2026, one of the most powerful tools in the enterprise fintech arsenal. Not despite its limitations, but thanks to a deliberate engineering response to each of them.