Patient-centric, AI-based, health record exchange platform that connects to a hospital’s patient management systems, and assembles and securely stores users’ health data. This platform allows patients to own their personal health data and share their information with other healthcare organizations should they choose to.
In 2026, the demand for scalable, interoperable, and secure healthcare platforms is greater than ever. Healthcare data is notoriously siloed, locked behind decades-old protocols, and heavily regulated by frameworks like HIPAA in the US, GDPR in the EU, the EU Medical Device Regulation (MDR), and equivalent regimes elsewhere.
The hardest problem in modern digital health is the “drop-off”: ensuring patients actually follow their prescribed treatments. In this article we will walk through the engineering reality of building a comprehensive Medication Adherence System that bridges Medical IoT, Electronic Health Records (EHR/EMR), pharmaceutical supply chains, and advanced analytics — wrapped in a gamified, patient-centric mobile experience.
The architecture has to be polyglot to handle the diversity of throughput and computational requirements. But we will see how Python acts as the lingua franca — orchestrating business logic, normalizing medical data, and powering the ML and data-science engines that give the platform its real value.
We will also dig into a tough integration story: connecting to national pharmaceutical traceability systems (DSCSA in the United States, EMVS under the EU Falsified Medicines Directive, Tatmeen in the UAE, and other equivalent schemes), and what it takes — both architecturally and bureaucratically — to do this at item level.
1. High-Level Architecture Overview
Before diving into code and technology choices, here is the high-level architecture:
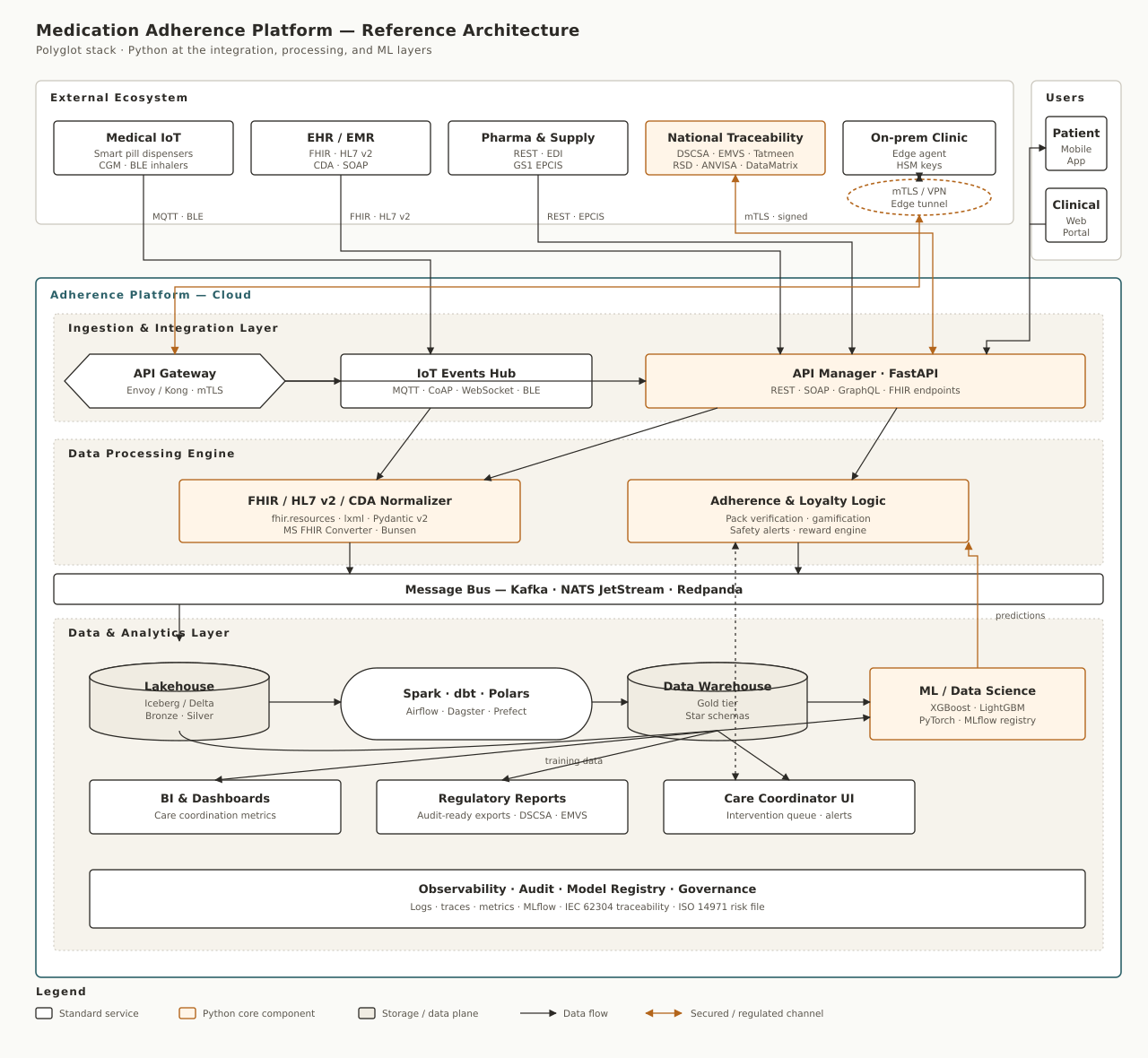
2. The Polyglot Philosophy: Right Tool for the Right Job
Looking at the architecture, it is immediately clear that a monolith does not fit. The system handles extreme variance in data velocity and volume:
- High-velocity, low-latency telemetry from Medical IoT devices (smart pill dispensers, continuous glucose monitors, BLE inhalers).
- Heavy, deeply structured payloads from EHRs over modern FHIR REST/GraphQL APIs and legacy HL7 v2 / SOAP interfaces.
- Batch and stream processing into a Lakehouse and Data Warehouse.
- Compute-intensive workloads for BI and Machine Learning.
A polyglot stack embraces these differences. A pragmatic 2026 split looks like this:
- API Gateway / edge routing: memory-safe, highly concurrent runtimes like Go (custom Envoy filters, Kong) or Rust for raw routing, mTLS termination, rate limiting.
- IoT Events Hub: Erlang/Elixir (BEAM VM, EMQX, VerneMQ) or Rust to manage tens of thousands of concurrent MQTT/WebSocket sessions from edge devices.
- Front-end: TypeScript with React/Next.js for web; Kotlin Multiplatform, Swift, or Flutter/Dart for mobile.
- Stream processing for tick-fast paths: Java/Scala (Flink, Kafka Streams) where guaranteed exactly-once semantics matter.
When data reaches the API Manager, the Data Processing Layer, the Feature Store, and the analytics environment, Python becomes the cornerstone. Python 3.12+ — with its async runtime, strict type hints (mypy / pyright), and the dominant ecosystem for data engineering, biomedical informatics, and machine learning — fits naturally.
3. Ingestion and API Management: The Python Interface
The ingestion layer is a universal translator. Healthcare is famously slow to deprecate anything, so an adherence platform must seamlessly support HL7 v2 over MLLP, CDA documents, and SOAP web services alongside modern FHIR REST and GraphQL.
By centralizing API adapter logic in Python we can use FastAPI (or Litestar) as an asynchronous backbone. Below is how protocol-agnostic entry points normalize inbound data and push it onto a message bus (Kafka, NATS JetStream, or Redpanda) for downstream processing.
import logging
from fastapi import FastAPI, Request
from zeep.client import AsyncClient # legacy SOAP/WSDL endpoints
import strawberry
from strawberry.fastapi import GraphQLRouter
logger = logging.getLogger(__name__)
app = FastAPI(title="Adherence Platform API Manager")
# 1. FHIR REST endpoint for modern EHR integrations
@app.post("/fhir/Encounter")
async def ingest_encounter(request: Request) -> dict:
payload = await request.json()
# Hand off to the normalization pipeline. event_bus is injected via DI.
await event_bus.publish("raw_encounter_topic", payload)
return {
"resourceType": "OperationOutcome",
"ingestion_id": payload.get("id"),
"status": "accepted",
}
# 2. GraphQL router for flexible frontend and partner queries
@strawberry.type
class AdherenceQuery:
@strawberry.field
async def patient_adherence_score(self, patient_id: str) -> float:
# The actual adherence calculation lives in the domain service
return await adherence_service.score(patient_id)
schema = strawberry.Schema(query=AdherenceQuery)
app.include_router(GraphQLRouter(schema), prefix="/graphql")
# 3. Async wrapper for legacy SOAP / WSDL endpoints (older hospital systems)
async def fetch_legacy_patient_demographics(identifier: str) -> dict:
async with AsyncClient(
wsdl="https://legacy-hospital-system.local/services/patient?wsdl",
) as client:
return await client.service.GetPatientDemographics(ID=identifier)By abstracting protocol complexity at the edge, the cognitive load on backend engineers drops dramatically. Downstream services see clean, validated payloads regardless of how the data originated.
4. Data Processing: Translating the Language of Healthcare
Once inside the platform perimeter, every payload is rigorously standardized. Two HL7 standards dominate:
- HL7 v2 / CDA — still the workhorse of hospital integrations worldwide.
- HL7 FHIR — the modern standard. R4 (Dec 2018) remains the de-facto production target, R5 (March 2023) is current Standard for Trial Use, and R6 is on track for late 2026 with most resources expected to reach normative status.
Parsing and validating FHIR resources is non-trivial because of deep nesting, mandatory terminology bindings (LOINC, SNOMED CT, RxNorm, ICD-10/11), and rich invariants. Python’s fhir.resources library — backed by Pydantic v2 — handles this declaratively.
Below the pipeline ingests a legacy CDA document, extracts a vital sign, and emits a strict FHIR Observation resource:
import logging
from fhir.resources.observation import Observation
from fhir.resources.quantity import Quantity
from lxml import etree # lxml handles CDA namespaces robustly
logger = logging.getLogger(__name__)
NSMAP = {"cda": "urn:hl7-org:v3"}
def cda_to_fhir_observation(cda_xml: bytes, patient_ref: str) -> Observation:
"""
Parse a legacy HL7 CDA document and map an extracted clinical value
into a strict FHIR Observation resource (Vital Signs profile).
"""
try:
tree = etree.fromstring(cda_xml)
# Production code uses templated XPaths against IHE templates;
# here we pretend we already extracted a systolic BP value.
bp_value = _extract_value(tree, loinc_code="8480-6", ns=NSMAP)
return Observation(
status="final",
category=[{
"coding": [{
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "vital-signs",
}],
}],
code={
"coding": [{
"system": "http://loinc.org",
"code": "8480-6",
"display": "Systolic blood pressure",
}],
},
subject={"reference": f"Patient/{patient_ref}"},
valueQuantity=Quantity(
value=bp_value,
unit="mmHg",
system="http://unitsofmeasure.org",
code="mm[Hg]",
),
)
except (etree.XMLSyntaxError, ValueError) as e:
logger.error("CDA → FHIR mapping failed: %s", e)
raiseFor large-scale conversions, teams typically combine fhir.resources with proven converters such as the Microsoft FHIR Converter (HL7 v2 / CDA / C-CDA → FHIR templates) or Bunsen for batch CDA → FHIR via Spark. Whichever tool is chosen, the goal is the same: whether data originated as a SOAP envelope, an old XML file, or a Bluetooth pillbox, in the lakehouse it lives in a universally searchable, FHIR-compliant form.
5. Core Business Logic: Pharmaceutical Traceability and Adherence Gamification
Self-reporting is not enough to verify medication adherence. We need hard evidence that the patient actually obtained the right medication. The platform integrates with national pharmaceutical traceability systems for that.
In modern track-and-trace, products are identified at item level. The standard global identifier is GTIN (Global Trade Item Number); when combined with a unique serial number per physical pack, the resulting GS1 EPC URI is commonly called an SGTIN (Serialized GTIN). The full set of attributes printed on every saleable pack — GTIN, serial number, batch/lot, expiry — is encoded into a GS1 DataMatrix 2D barcode under both EU FMD and US DSCSA.
Regulatory landscape (2026)
| Region | Scheme | Repository / network | Code carrier |
| United States | DSCSA (Drug Supply Chain Security Act) | Interoperable EPCIS networks between trading partners | GS1 DataMatrix, NDC + serial |
| European Union + EEA | EU FMD / Delegated Regulation 2016/161 | EMVS hubs operated by EMVO and national NMVOs | GS1 DataMatrix, GTIN + serial |
| United Arab Emirates | Tatmeen | National central repository | GS1 DataMatrix |
| Saudi Arabia | RSD (Saudi Drug Track and Trace) | National repository | GS1 DataMatrix |
| Türkiye, Brazil (ANVISA), India, etc. | Country-specific track-and-trace | National repositories | GS1-aligned 2D codes |
Most schemes share a common backbone: GS1 EPCIS as the event data standard (commissioning, aggregation, shipment, dispense), exchanged via REST/AS2/SFTP. National flavours layer their own authentication, signing, and lifecycle states on top.
Adherence flow
- Scan: the patient opens the mobile app and scans the GS1 DataMatrix on the medication pack.
- Verify: the platform queries the relevant national/regional verification API for the unit.
- Decide: if the unit’s lifecycle state is consistent with a legal dispense to a patient, the physical-acquisition step of adherence is marked complete.
- Reward: the patient earns in-app loyalty points that unlock premium content, partner discounts, or — in some markets — insurance premium reductions, gamifying adherence.
Python implementation
A unit lookup typically returns a structured response describing the pack’s product, batch, and current lifecycle state. Across schemes the state vocabulary varies, but it usually maps to a small set of conceptual statuses:
- active — the unit is in the supply chain and not yet dispensed.
- dispensed — legally dispensed to a patient (the success state for adherence).
- decommissioned — destroyed, sampled, exported, or otherwise removed from circulation.
- suspect / recalled — the unit (or its batch) has been suspended from circulation. Safety-critical state.
- unknown — the registry has no record of this serial number under this GTIN. Possible counterfeit.
import httpx
from datetime import datetime
from typing import Literal, Optional
from pydantic import BaseModel, Field
UnitState = Literal["active", "dispensed", "decommissioned", "suspect", "unknown"]
class PackLifecycleInfo(BaseModel):
gtin: str
serial_number: str
state: UnitState
state_changed_at: datetime
batch_number: str
expiry_date: Optional[datetime] = None
product_name: str = Field(alias="productName")
is_controlled_substance: bool = False
class TraceabilityClient:
"""Adapter for any GS1-aligned national traceability API (EMVS, DSCSA partner network, Tatmeen, ...)."""
def __init__(self, base_url: str, mtls_cert: tuple[str, str], oauth_token: str) -> None:
self.base_url = base_url
self.mtls_cert = mtls_cert # (cert_path, key_path)
self.headers = {
"Accept": "application/json",
"Authorization": f"Bearer {oauth_token}",
}
async def verify_pack(self, gtin: str, serial: str) -> PackLifecycleInfo:
async with httpx.AsyncClient(
cert=self.mtls_cert,
timeout=httpx.Timeout(10.0, connect=3.0),
) as client:
resp = await client.get(
f"{self.base_url}/v1/packs/{gtin}/{serial}",
headers=self.headers,
)
resp.raise_for_status()
return PackLifecycleInfo.model_validate(resp.json())
async def process_medication_scan(
user_id: str,
gtin: str,
serial: str,
registry: TraceabilityClient,
) -> dict:
try:
pack = await registry.verify_pack(gtin, serial)
except httpx.HTTPStatusError as e:
logger.error("Registry lookup failed: HTTP %s", e.response.status_code)
raise PlatformIntegrationError("Unable to reach traceability registry") from e
# 1. Clinical safety: recalled / suspended
if pack.state == "suspect":
await trigger_clinical_safety_alert(user_id, pack)
return {
"status": "danger",
"message": f"Critical: {pack.product_name} has been suspended from circulation.",
}
# 2. Counterfeit signal
if pack.state == "unknown":
await flag_potential_counterfeit(user_id, gtin, serial)
return {
"status": "danger",
"message": "This pack is not recognised by the registry. Do not consume.",
}
# 3. Adherence success path
if pack.state == "dispensed":
await link_pack_to_patient(user_id, gtin, serial)
await award_adherence_points(user_id, action="verified_scan", points=50)
return {
"status": "success",
"message": "Medication verified. Adherence points awarded.",
}
# 4. Anything else (active in supply chain, decommissioned) is a soft warning
return {
"status": "warning",
"message": f"Pack is currently in state: {pack.state}.",
}The data model and the state machine are deliberately scheme-agnostic. The actual EMVS, DSCSA, or Tatmeen response is mapped into this canonical shape inside each TraceabilityClient adapter, so the business logic above does not change when the platform expands into a new market.
6. The Bureaucratic Reality of Traceability Integration
Writing the integration code is the easy part. Getting legal and technical access to these state-run or industry-run registries is the real engineering challenge.
National traceability systems are designed for direct participants in the pharmaceutical lifecycle: manufacturers, marketing-authorisation holders, wholesalers, and licensed dispensers (pharmacies, hospitals). An aggregator, a patient adherence platform, or a wellness portal does not naturally fit any of these roles.
Practical access typically requires some combination of:
- Trading-partner registration — verified company identity, pharma licence, signed data agreements.
- mTLS client certificates issued by the registry, often tied to specific environments (sandbox / production).
- Cryptographic signing of requests using hardware-backed keys (HSM, smart card, or cloud KMS with FIPS 140-2/3 level 2+ assurance).
- OAuth 2.0 / OIDC with strict scope, audience, and lifetime constraints.
- Audit logging of every lookup with non-repudiation guarantees.
To solve the access problem, an adherence platform usually forms strategic partnerships with licensed pharmacy chains, telemedicine providers, or hospital networks. The architectural pattern is to deploy an on-premise edge agent — a hardened container (Kubernetes/Docker) sitting inside the partner’s secure perimeter. The edge agent uses the partner’s HSM-protected keys to sign requests, calls the registry on behalf of the platform, and tunnels the sanitized, de-identified result back through an mTLS / VPN link to the platform’s API gateway.
Because public documentation for these APIs is often partial or hidden behind partner portals, defensive programming is mandatory: aggressive schema validation on responses, circuit breakers per registry, idempotent retries on transient failures, and graceful UI messaging when a registry is unavailable.
7. Storage Layer: Lakehouse and ETL Pipelines
As the diverse streams pour in — normalized FHIR resources, parsed IoT telemetry, enriched pack-verification events — they land in the Lakehouse.
By 2026 the dominant pattern is open table formats (Apache Iceberg or Delta Lake) on top of object storage (S3, ADLS, GCS). The Medallion Architecture — Bronze (raw), Silver (clean, conformed), Gold (aggregated for consumption) — is canonical.
Orchestration is typically done with Apache Airflow, Dagster, or Prefect; transformations are written in PySpark, Polars, or dbt. Below is a Spark + Delta example for a daily adherence telemetry pipeline:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, window
spark = (
SparkSession.builder
.appName("Adherence_ETL_Pipeline")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
)
def process_daily_adherence_telemetry() -> None:
# 1. Bronze: raw, semi-structured IoT events and medication scans
df_raw = spark.read.format("delta").load("s3a://adherence-lake/bronze/patient_events")
# 2. Silver: cleaned, deduplicated, schema-enforced
df_clean = (
df_raw
.select(
col("patient_id"),
col("event_type"), # 'med_scan' | 'pillbox_opened' | 'sensor_reading'
col("gtin"),
col("serial_number"),
col("timestamp"),
)
.filter(col("event_type").isNotNull())
.dropDuplicates(["patient_id", "event_type", "timestamp"])
)
(df_clean.write
.format("delta")
.mode("append")
.save("s3a://adherence-lake/silver/patient_events"))
# 3. Gold: aggregated daily fact for dashboards and ML
df_daily = (
df_clean
.groupBy("patient_id", window("timestamp", "1 day"))
.count()
.withColumnRenamed("count", "daily_interaction_count")
)
(df_daily.write
.format("jdbc")
.options(
url="jdbc:postgresql://dwh-cluster:5432/analytics",
dbtable="fact_daily_adherence",
user="etl_service_account",
# In production this comes from a secrets manager (Vault, AWS Secrets Manager, ...)
password=secrets.get("dwh_etl_password"),
)
.mode("append")
.save())The Gold tier feeds the BI and Reporting modules — letting clinical administrators, care coordinators, and pharma partners monitor real-time adherence rates, demographic trends, and supply-chain anomalies.
8. Machine Learning: Predictive Adherence and Supply Analytics
A reliable lakehouse and warehouse mean the ML and Data Science layer becomes the platform’s main differentiator. Because the underlying data plumbing is Python, pushing data into ML pipelines is frictionless.
Using scikit-learn, XGBoost, LightGBM, and PyTorch, the platform can deliver, among others:
- Therapy-drop-off (churn) prediction. Correlating scan frequency and IoT telemetry with EHR clinical history, a gradient-boosting classifier (XGBoost/LightGBM is the canonical workhorse for tabular healthcare data) predicts a patient’s probability of abandoning therapy in the next N days. Above a threshold, the platform automatically triggers an intervention — a push notification, an SMS, a tele-consult invite, or a task for a human care coordinator.
- Supply-chain anomaly detection. If the rate of suspect or unknown statuses spikes for a specific batch in a specific geography, an unsupervised model (Isolation Forest, autoencoder reconstruction error, or change-point detection) flags potential counterfeit infiltration or distribution disruption to regulators and pharma partners.
- Optimal reminder timing. Reinforcement learning or contextual bandits learn the per-patient time-of-day with the highest scan-completion rate, reducing notification fatigue.
The model lifecycle
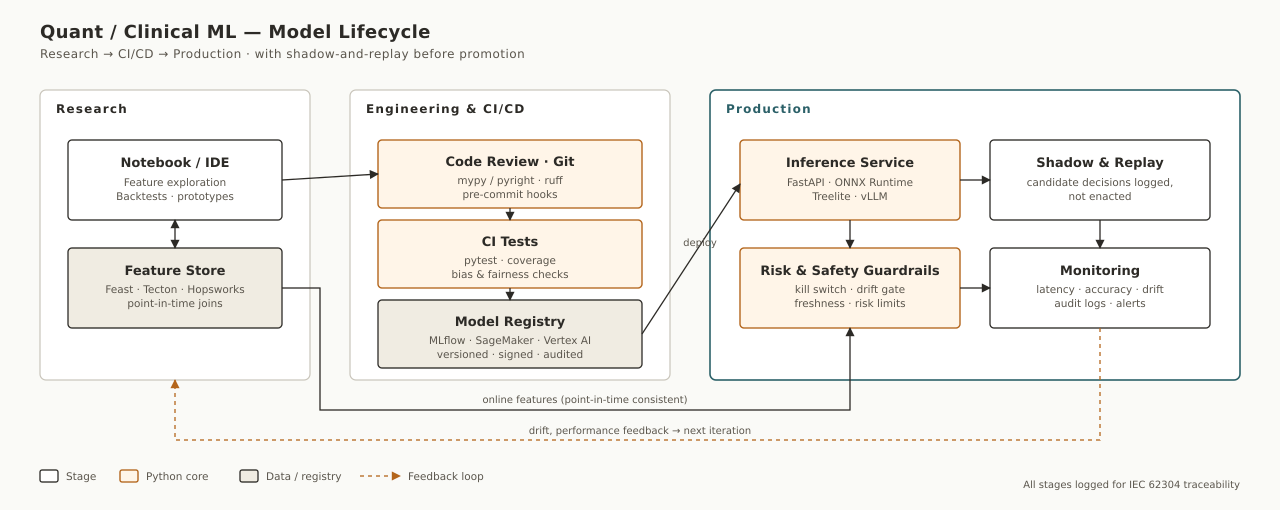
The shadow-and-replay stage is non-negotiable for clinical models: a candidate model runs alongside the production one for weeks, its decisions logged but not enacted. Only after the candidate proves at least equivalent on patient outcomes does it get promoted.
9. Security, Compliance, and Edge Infrastructure
Handling Protected Health Information (PHI) and Personally Identifiable Information (PII) demands uncompromising security. A platform like this must be built from day one against multiple regulatory frameworks: HIPAA in the US, GDPR in the EU, UK GDPR, PIPEDA in Canada, LGPD in Brazil, and country-specific health-data laws elsewhere.
- Data at rest and in transit. AES-256 at rest; TLS 1.2+ (preferably 1.3) in transit; mTLS between internal services in a zero-trust mesh (Istio / Linkerd / Consul).
- De-identification pipelines. Before patient data flows from Silver into ML training environments, libraries like Microsoft Presidio detect and redact PII (names, addresses, phone numbers, MRNs). For deeper de-identification of free-text clinical notes, specialized tools — Stanford’s Philter, NLM Scrubber, or commercial offerings — handle the long tail of identifiers (dates, geography, rare conditions). The goal: ML models train on clinical signal, not on patient identity.
- k-anonymity / differential privacy. For data shared with external research partners, apply k-anonymity (every record indistinguishable from at least k-1 others on quasi-identifiers) or differential privacy budgets, tracked per dataset.
- Software as a Medical Device (SaMD). A platform whose outputs directly influence patient behaviour or clinical decisions very likely qualifies as SaMD. The relevant standards are:
- IEC 62304 — software lifecycle processes for medical device software (the core standard);
- ISO 14971 — risk management for medical devices;
- ISO 13485 — quality management system;
- regional regulations on top: EU MDR 2017/745, US FDA 21 CFR Part 820 / Quality System Regulation, and equivalent national rules.
- Under IEC 62304, every code change in the Python microservices must be traceably linked to a software requirement; classified into a software safety class (A / B / C); covered by appropriate verification and validation; and recorded in a controlled software-of-unknown-provenance (SOUP) inventory for every dependency.
- Audit trail and non-repudiation. Every PHI access, every external registry lookup, and every decision that influences a patient is written to an append-only, signed audit log — for regulators, for internal compliance, and for forensic incident response.
Conclusion
Building a medication adherence system in 2026 means balancing cutting-edge engineering with rigid regulatory constraints. The architecture is unavoidably polyglot — from massively concurrent IoT ingestion to high-performance edge routing to mobile front-ends — but Python is the indispensable glue of the modern health-tech stack.
By using Python for robust API management, complex standard translation (HL7 v2 / CDA → FHIR), pharmaceutical traceability integration with GS1-aligned registries, and predictive analytics, engineers can hide the underlying chaos of healthcare data behind a clean domain model. With thoughtful software architecture and disciplined adherence to compliance standards (IEC 62304, ISO 14971, ISO 13485, plus regional regimes), fragmented healthcare silos can be reshaped into a transparent, patient-rewarding, and ultimately life-saving digital ecosystem.